
Video Synthesis from a Single Image
Abstract
In this work a novel architecture is developed to perform video prediction. In particular the task of "bringing landscape images to live" is investigated. This is an especially challenging video prediction task, as only a single input image is given and the model has to predict what might happen next in the scene, for example clouds moving or flowing rivers and waterfalls. The changes per frame in these types of videos are usually very small detailed. As no flow or segmentation is given the model also has to learn, which image elements to animate. The proposed architecture combines recurrent, feature pyramid architectures from previous works such as DVD-GAN with styled convolutions introduced by StyleGAN to predict the final video. A new dataset for the task of "bringing landscape images to live", which focuses on fine details rather than global changes. The proposed model is evaluated against state-of-the-art baselines and is shown to also work on standard video prediction benchmarks, while requiring smaller compute resources for training.
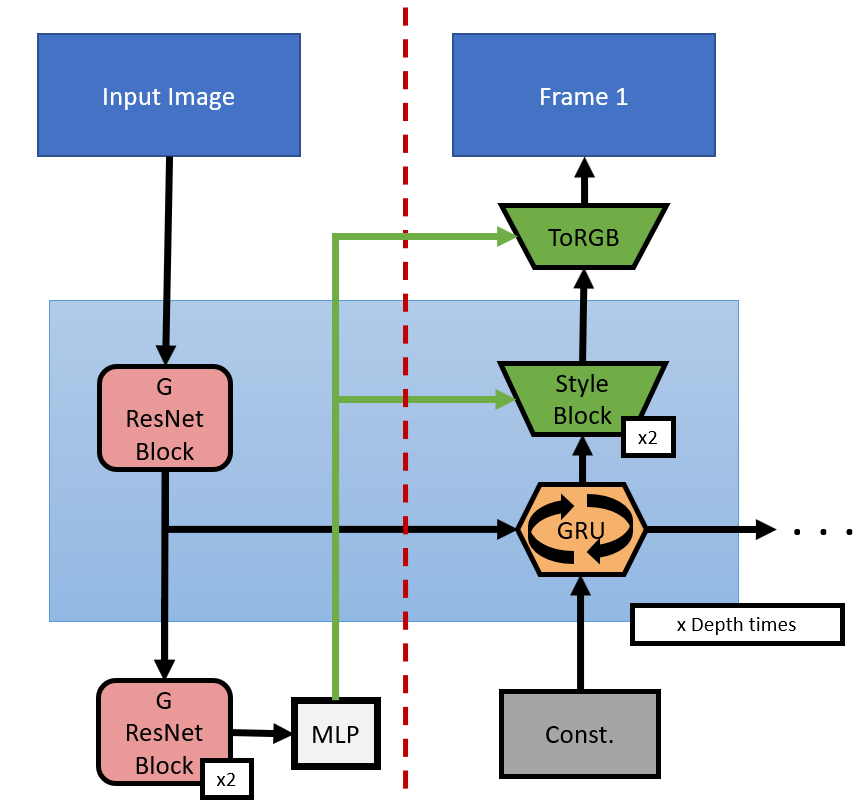
Video prediction architecture based on StyleGAN2 and DVD-GAN. The green arrow indicates the predicted style vector. The dashed red line logically separates the generator into an encoder and decoder part.
Showcase: Sky Timelapse Dastaset
Showcase: Custom Dastaset
Comparison
Comparison between our method (top) and a down-scaled version of DVD-GAN (bottom) on the bair robot pushing dataset.
Showcase: GauGAN videos
Video prediction on images created with GauGAN. The video prediction model was trained on our custom dataset.
Advisor: Justus Thies
Supervisor: Matthias Nießner
Presentation
Paper
Project Page
Github